随着大数据时代的到来,汽车行业对销售数据的深度挖掘与可视化呈现需求日益增长。本文将详细介绍基于Python技术栈构建的汽车销售数据采集分析可视化系统,该系统整合了Flask框架、网络爬虫、大数据处理和数据可视化等关键技术,实现了从数据采集到可视化展示的完整业务流程。
一、系统架构设计
本系统采用分层架构设计,主要包含数据采集层、数据处理层、业务逻辑层和可视化展示层:
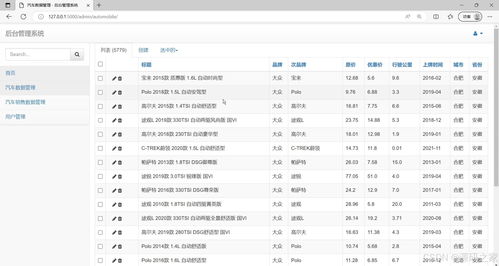
- 数据采集层:基于Python爬虫技术,通过Requests、BeautifulSoup、Selenium等库,从汽车之家、易车网等主流汽车网站自动采集销售数据,包括车型信息、价格走势、销量统计、用户评价等多维度数据。
- 数据处理层:采用Pandas、NumPy等数据处理库对采集的原始数据进行清洗、去重、格式转换和特征工程,同时结合PySpark处理海量数据,确保数据质量和处理效率。
- 业务逻辑层:基于轻量级Flask框架构建Web服务,提供RESTful API接口,实现用户管理、数据查询、分析计算等核心业务功能。
- 可视化展示层:通过ECharts、Pyecharts等可视化库,结合HTML5、CSS3和JavaScript技术,构建交互式可视化大屏,实时展示销售趋势、区域分布、车型对比等关键指标。
二、核心技术实现
1. Flask框架应用
Flask作为轻量级Web框架,提供了灵活的路由机制、模板渲染和扩展支持。系统通过Flask-Blueprint实现模块化开发,使用Flask-SQLAlchemy进行数据库操作,Flask-Login处理用户认证,确保系统的可维护性和安全性。
2. 智能爬虫系统
针对不同数据源设计差异化爬取策略:对静态页面使用Requests+BeautifulSoup组合;对动态加载内容采用Selenium模拟浏览器行为;通过设置合理的请求间隔、User-Agent轮换和IP代理池,有效规避反爬机制。
3. 大数据处理流程
建立完整的数据流水线:原始数据存入MySQL数据库,通过Pandas进行初步清洗和预处理,对于TB级数据采用PySpark分布式计算,最终将处理结果存储至Redis缓存,提升数据查询性能。
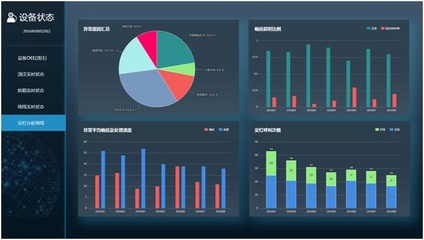
4. 可视化大屏设计
可视化大屏采用响应式布局,适配不同尺寸的显示设备。关键可视化组件包括:
- 销售趋势折线图:展示月度/季度销售变化
- 区域分布热力图:呈现各地区销售热度
- 车型销量占比饼图:显示各车型市场份额
- 价格区间分布直方图:分析价格集中区间
- 实时销售排行榜:动态更新热销车型
三、系统特色与优势
- 全流程自动化:实现从数据采集、处理到可视化展示的全流程自动化,大幅提升工作效率。
- 实时数据更新:通过定时任务调度,确保数据的时效性,支持实时监控销售动态。
- 多维度分析:提供时间、地域、车型、价格等多维度分析视角,助力决策支持。
- 高可扩展性:模块化设计便于功能扩展,支持新增数据源和可视化组件。
四、应用场景与价值
本系统适用于汽车制造商、经销商、市场研究机构等多个场景:
- 销售决策支持:通过历史数据和趋势分析,优化库存管理和营销策略
- 市场竞争分析:监控竞品销售表现,及时调整市场定位
- 用户行为洞察:分析用户偏好,指导产品开发和精准营销
- 区域市场规划:基于地域销售特征,合理分配资源
五、技术展望
系统将进一步整合机器学习算法,实现销售预测、用户画像构建等智能分析功能;同时考虑引入Docker容器化部署,提升系统的可移植性和运维效率;还将探索与物联网设备的对接,获取更丰富的车辆使用数据。
基于Python的汽车销售数据采集分析可视化系统,通过整合爬虫技术、大数据处理和Web开发,构建了完整的数据价值链。该系统不仅提供了强大的数据分析能力,更通过直观的可视化展示,将复杂数据转化为易于理解的商业洞察,为汽车行业的数字化转型提供了有力支撑。