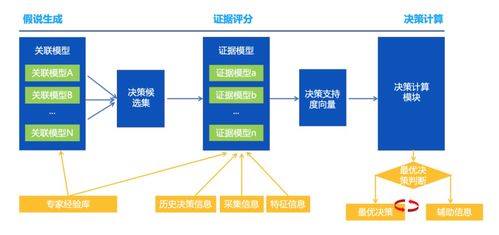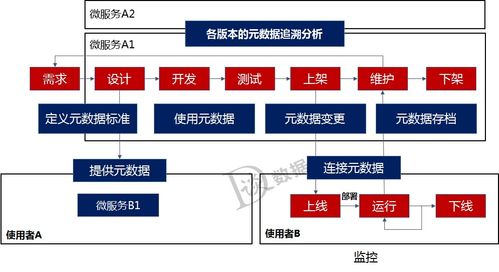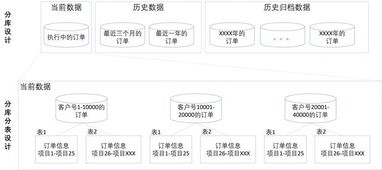
在微服务架构中,数据架构设计和数据处理服务的合理规划是系统成功的关键因素。微服务的核心理念是将单一应用拆分为多个小型、自治的服务,每个服务负责特定的业务功能。这种拆分带来了数据管理的复杂性,因此需要精心设计数据架构以确保系统的可扩展性、可靠性和一致性。
一、微服务数据架构设计原则
- 数据自治:每个微服务应拥有自己的数据库,避免服务间直接共享数据存储。这有助于减少耦合,使服务能够独立开发、部署和扩展。例如,订单服务管理订单数据,用户服务管理用户信息,两者通过明确定义的API进行交互。
- 数据隔离与边界:基于领域驱动设计(DDD)的界限上下文,明确每个服务的数据边界。这可以防止数据泄露和不当访问,确保业务逻辑的清晰性。设计时需考虑数据的生命周期和所有权,避免跨服务的数据依赖。
- 事件驱动架构:为了处理跨服务的数据一致性,推荐采用事件驱动模式。例如,使用消息队列(如Kafka或RabbitMQ)发布事件,当某个服务的数据发生变化时,其他服务可以通过订阅事件来更新自己的数据副本,实现最终一致性。
- 数据冗余与去规范化:在微服务中,为了提高查询效率,可以适度引入数据冗余。例如,订单服务可能存储用户的基本信息(如用户名),以避免频繁调用用户服务。但需注意数据同步机制,防止不一致问题。
- 可扩展性与性能:选择适合的数据库类型,如关系型数据库(MySQL、PostgreSQL)用于事务性强的服务,NoSQL数据库(MongoDB、Cassandra)用于高吞吐量场景。利用缓存(如Redis)和分片技术来提升性能。
二、数据处理服务的角色与实现
数据处理服务在微服务架构中负责数据的采集、转换、存储和分析,确保数据流的高效和可靠。它通常包括以下关键组件:
- 数据 ingestion 服务:负责从各种源(如用户输入、外部API或事件流)收集数据。例如,使用Apache Flume或自定义服务将日志数据导入数据湖。设计时应考虑数据格式标准化和错误处理,以防止数据丢失。
- 数据转换与清洗服务:对原始数据进行处理,去除噪声、验证完整性,并转换为目标格式。这可以通过ETL(提取、转换、加载)工具或流处理框架(如Apache Spark或Flink)实现。例如,一个微服务可能调用数据处理服务来规范用户地址信息。
- 数据存储与查询服务:提供统一的数据访问接口,支持其他微服务查询和分析数据。这包括实现数据仓库或数据湖架构,使用OLAP数据库(如ClickHouse)或搜索引擎(如Elasticsearch)来加速复杂查询。
- 数据一致性服务:在分布式环境中,处理数据一致性问题至关重要。可以采用Saga模式或两阶段提交(2PC)来管理跨服务事务,或使用补偿事务处理失败情况。
- 监控与治理服务:集成监控工具(如Prometheus或Grafana)来跟踪数据流性能、延迟和错误率。实施数据治理策略,包括数据加密、访问控制和合规性检查,以保障数据安全。
三、最佳实践与挑战
在实践中,微服务数据架构设计需平衡灵活性与复杂性。建议采用以下最佳实践:
- 逐步演进:从核心服务开始,逐步拆分数据,避免一次性重构。
- API优先设计:通过REST或gRPC接口暴露数据,确保服务间通信的标准化。
- 测试与回滚策略:对数据处理服务进行充分测试,特别是涉及数据迁移时,准备回滚机制以应对故障。
挑战包括数据一致性问题、网络延迟和运维成本。通过采用云原生技术(如容器化和服务网格)和自动化工具,可以有效缓解这些挑战。
微服务开发中的数据架构设计和数据处理服务需要以业务需求为导向,结合现代技术栈,构建高可用、可扩展的系统。通过遵循上述原则和实践,团队可以更好地管理数据复杂性,推动业务创新。